[Paper Review] f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks
2020. 8. 9. 12:04ㆍDeepLearning/GAN
f-AnoGAN
- Authors : Thomas Schleg,Philipp Seeböck, Sebastian M.Waldstein, Georg Langs,Ursula Schmidt-Erfurth
- Journal : Medical Image Analysis (Impact Factor: 11.148 in 2020)
- Summary :
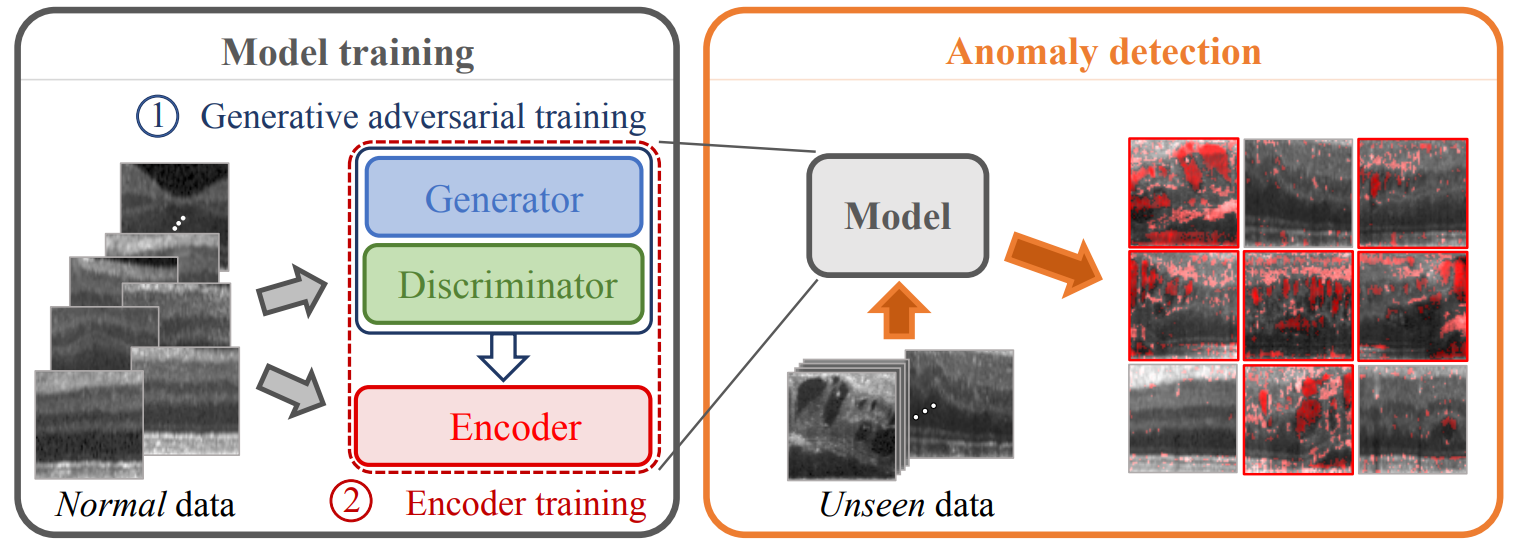
- 기존 AnoGAN가 inference할 때 iterative optimization 의 느린 속도를 개선하고자 encoder 기반의 구조를 제안하였다. 또한, 다양한 encoder 학습 방법을 제안하였다.
- Architecture : Wasserstein GAN + Encoder
- Encoder based Anomaly Detection
- Encoder enables A fast learned mapping technique of new data to the GAN's latent space
- Not an iterative gradient descent approach from AnoGAN
- Reconstruction based Anomaly Score (same approach from AnoGAN)
- L1 distance
- Feature distance (discriminator's intermediate layer)
Training Method
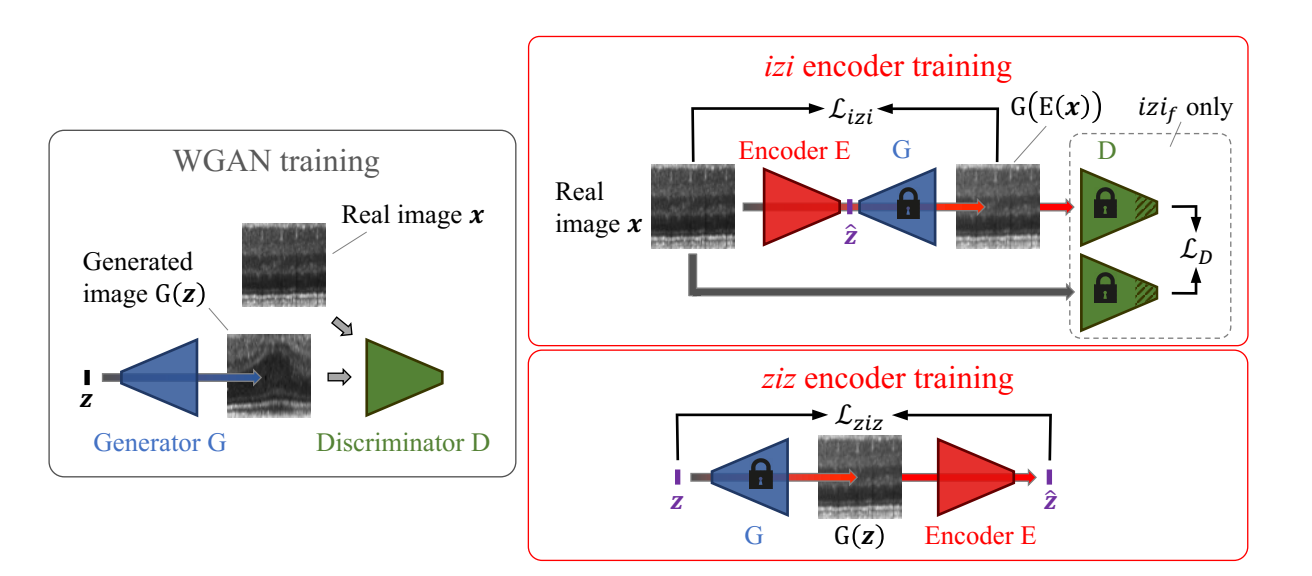
- GAN training on images from normal scans
- Learning normal anatomical variability with a generative adversarial network
- Encoder training based on the trained GAN model
- Training the encoder with generated images: ziz architecture
- minimize the mean squared error (MSE) of input z-samples z and reconstructed z-samples E(G(z))
- Drawback
- the encoder only “sees” generated images but never receives real input image
- Since the ziz encoder training objective operates in the latent space only, even normal query images are reconstructed with limited accuracy during anomaly detection.
- Training the encoder with real images: izi architecture
- A standard Auto Encoder configuration
- Minimize the MSE residual loss of input images x and reconstructed images G(E(x))
- much more smoother reconstructions than ziz architecture
- Drawback
- Since the true target location in the z-space of a given query image is unknown, we can indirectly measure the accuracy of the image to z mapping through mapping back to the image space and computing the image-to-image residual.
- Only minimizing pixel-wise differences will occasionally yield images that are not realistic examples of normal image
- A discriminator guided izi encoder training: izi_f architecture
- The feature matching technique proposed in Salimans et al. (2016)
- izif architecture simultaneously guides encoder trainingin the image space and in the latent space
- Training the encoder with generated images: ziz architecture
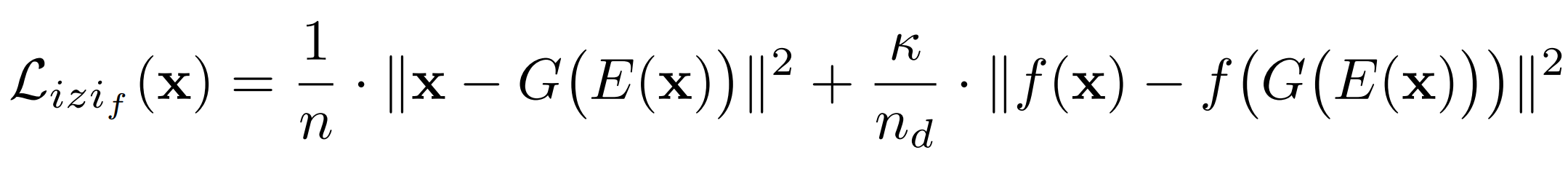
Anomaly Score
Classification
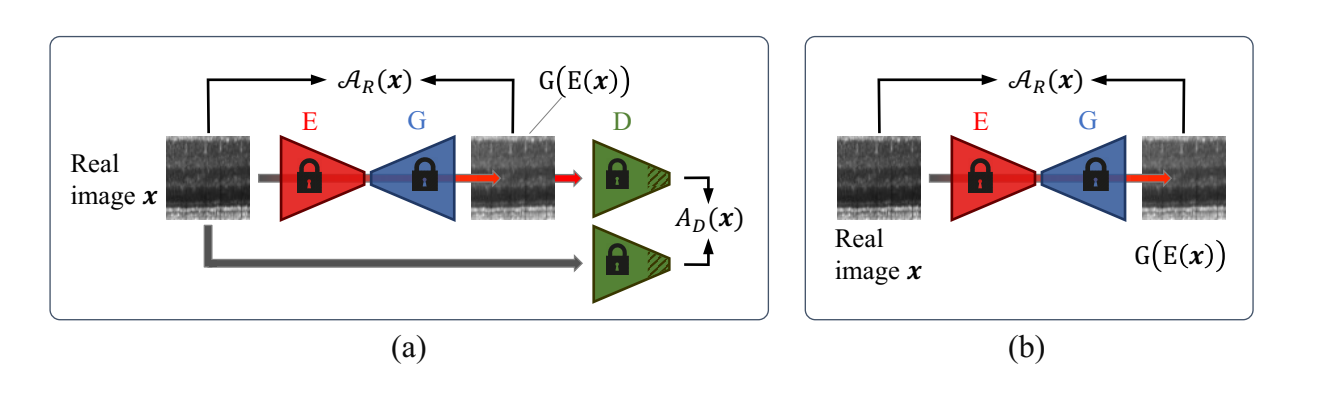
- Classification: Reconstruction error based Anomaly Score (same approach from AnoGAN)
- L1 distance (pixel-level)
- Discriminator feature distance
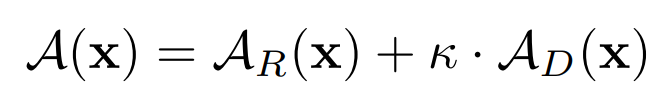
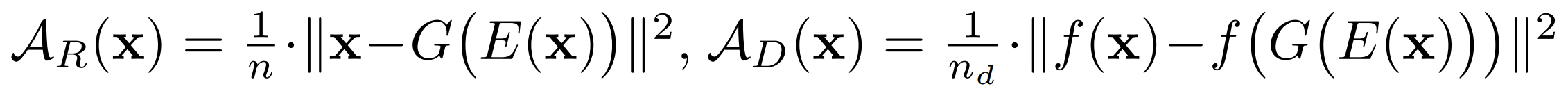
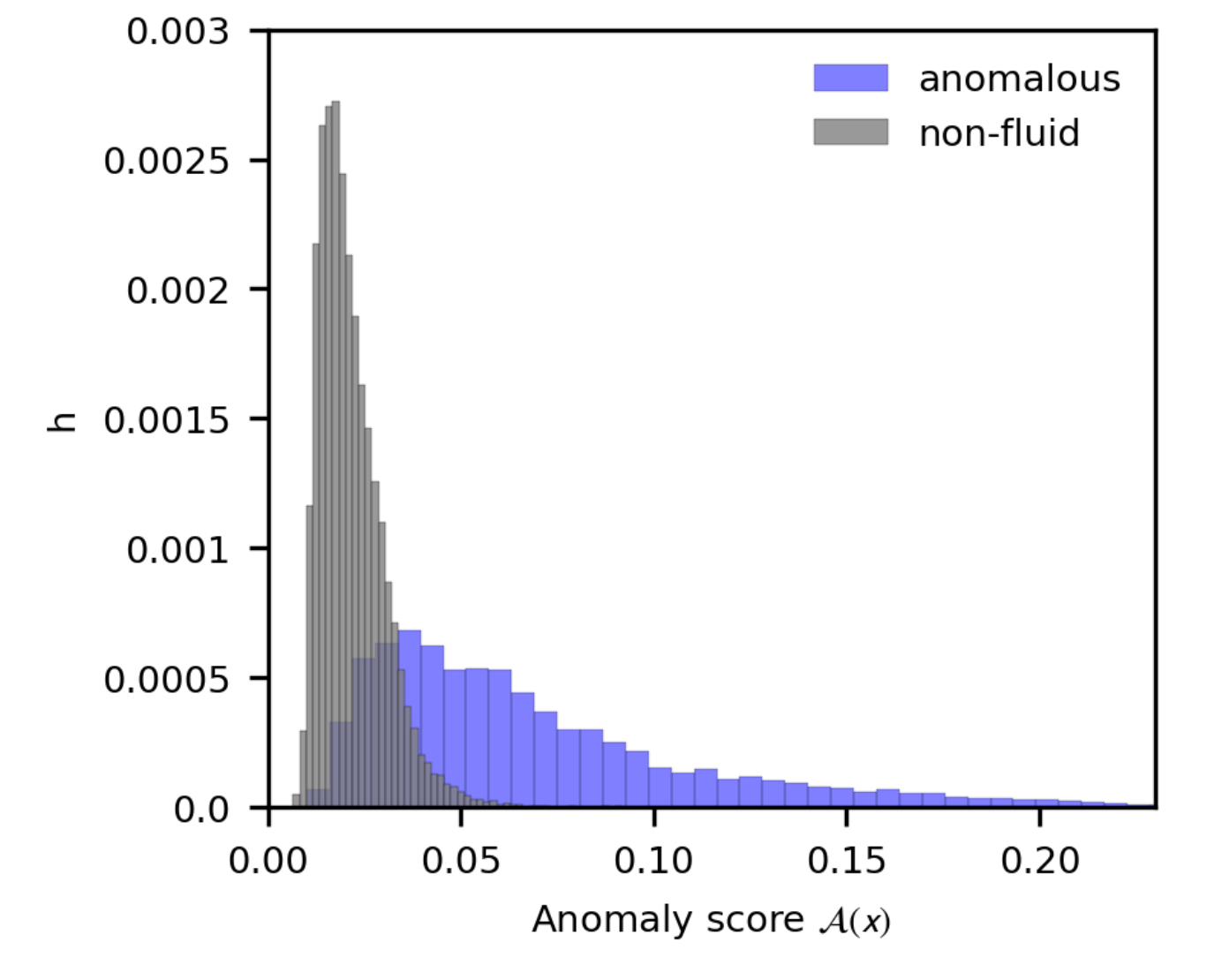
Pixel-level anomaly localization
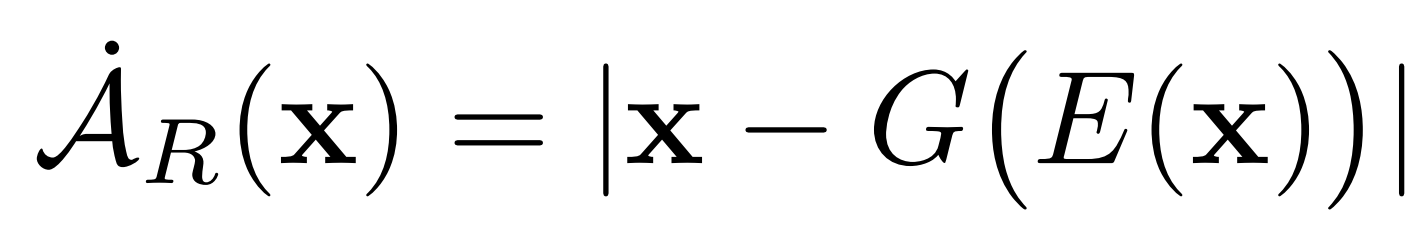
Limitations
- Low Resolution
- In clinical practice, OCT diagnosis is not performed at such small scale (64x64 pixels
- Therefore, this task does not reflect the performance of the clinical retina experts on full OCT cross-sectional images.
- In clinical practice, OCT diagnosis is not performed at such small scale (64x64 pixels
- Not a good performance at localization: The quantitative evaluation of segmentation accuracy of anomaly detection only serves as a coarse indication to show that it can localize anomalies.
- Annotations
- “false positives” might be true anomalies not part of the annotated category.
Appendix
Constraining encoder outputs
The authors restrict the encoder to map normal images into the range (−1σ, +1σ) of the standard normal distribution by implementing a tanh activation function on the output layer of the encoder.
- only possible when using a normal distribution (as opposed to a uniform distribution) for sampling z locations during WGAN training.
- consistently yields a gain in accuracy for all the examined encoder architectures in direct comparison to an utilization of a linear output layer.
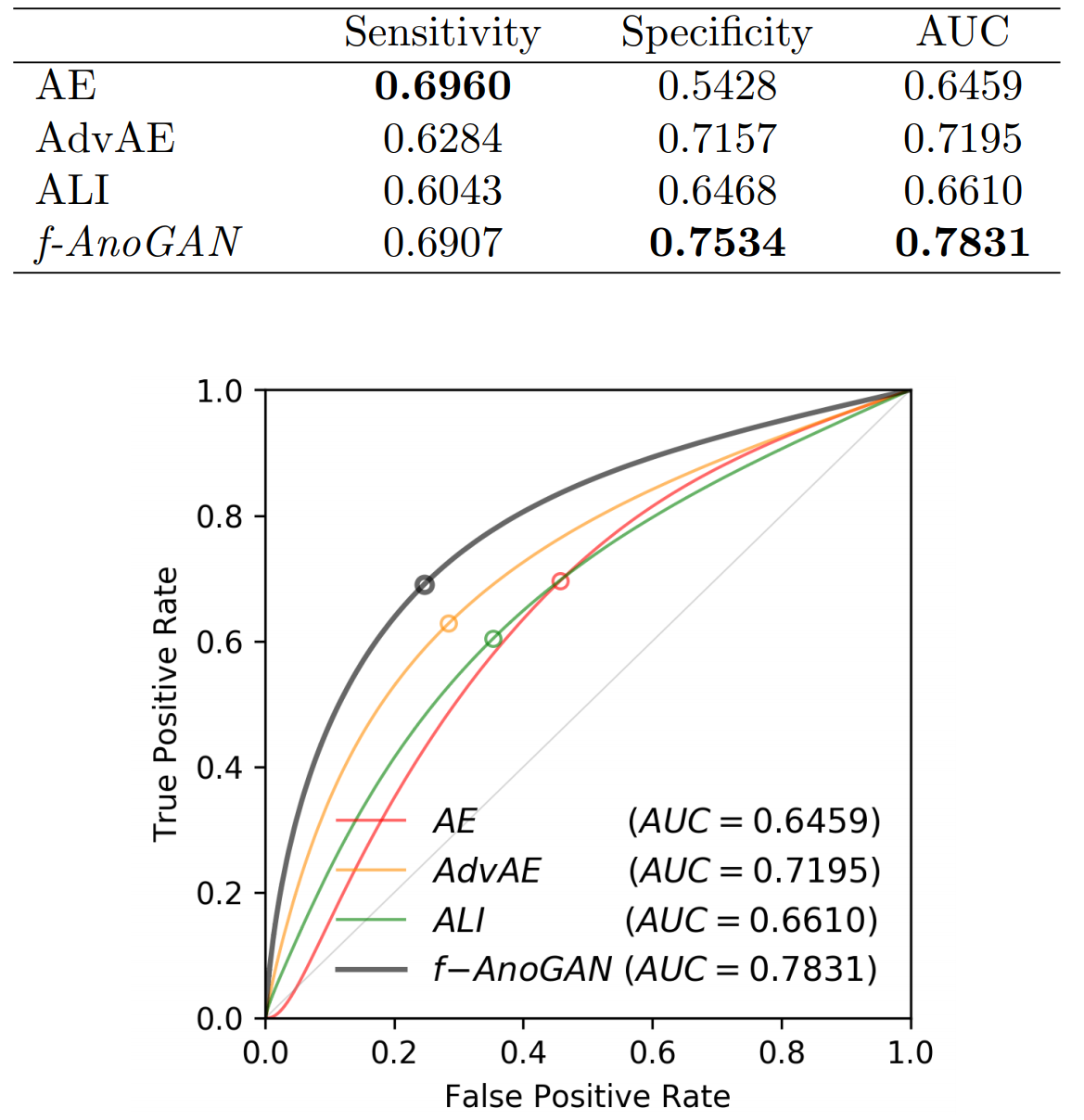
- Drawbacks in Other structure for Anomaly Detection
- AutoEncoders (AE and AdvAE)
- AE over-adapts to anomalous image regions, which leads to worst anomaly localization performance.
- AdvAE yields good anomaly localization performance but performs equally to the AE on anomaly detection
- ALI shows overall good realistic image “reconstructions” but the query and “reconstructed” images also deviate in visual appearance, i.e. although they show similar semantic content deviate in their specific pixellevel appearance
- AutoEncoders (AE and AdvAE)
'DeepLearning > GAN' 카테고리의 다른 글
| [Paper Review] GANSpace: Discovering Interpretable GAN Controls (0) | 2020.08.27 |
|---|---|
| [Paper Review]Skip-GANomaly (0) | 2020.08.12 |
| [Paper Review] GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training (0) | 2020.08.10 |
| [Paper review] StyleGAN2 (0) | 2020.07.28 |
| [Paper Review] StyleGAN (0) | 2020.07.27 |