2020. 7. 27. 13:48ㆍDeepLearning/GAN
StyleGAN: A Style-Based Generator Architecture for GANs

We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
제목 : A Style-Based Generator Architecture for Generative Adversarial Networks
저자 : Tero Karras, Samuli Laine, Timo Aila
기관 : NVIDIA
학회 : CVPR 2019
요약 :
- Mapping Network f
- Mapping function of randomly initialized Latent code z to intermediate Latent code w
- Better disentangled representation and interpolation property
- Synthesis Network g
- Scale specific control of the image synthesis.
- AdaIN (A) : mapping 된 latent w ~ W는 일련의 affine transformation, AdaIN operation을 통해 각 convolutions block에 scale-specific한 style로 이용된다.
- 각 Convolutional Layer에 w을 affine transformation과 AdaIN으로 특징의 분리와 scale specific control을 갖게 한다.
- Stochastic Variation (B) : style과 더불어 noise image input을 convolution block에 주입함으로써 생성되는 이미지들의 다양성과 자연스러운 stochastic variation을 줌.
- Style Mixing : 단순히 두 w을 특정 convolutional layer에 어떻게 주입하느냐에 따라 두 가지 혹은 그 이상의 다양한 Style을 특정 scale에 따라 섞을 수 있음.
- New Interpolation and Disentanglement Metric
- latent space의 Interpolation과 disentanglement 에 대한 정량적인 비교를 위한 새로운 measurement 방법인 perceptual path length와 linear separability를 제시
- FFHQ(Flickr-Faces-HQ, FFHQ) 데이터셋 제안
- A new dataset of human faces that offers much higher quality and covers considerably wider variation than existing high-resolution datasets
- Mapping Network f
Keywords : AdaIN, intermediate latent space, scale-specific, stochastic variation, disentanglement, perceptual path length
다음 영상을 참고하면 더 직관적으로 이해할 수 있다: https://www.youtube.com/watch?v=kSLJriaOumA

Progressive Growing of GAN (PGGAN)에서는 고해상도 이미지 학습에 한계를 갖고 있던 GAN의 구조를 바꾸어, 저해상도 이미지 (4x4)부터 고해상도 이미지 (1024X1024)로 점진적으로 생성하는 구조로 변경한 PGGAN을 제안하였다. 해상도를 높이는 네트워크가 추가되어도, 저해상도 이미지를 생성하는 Generator와 이를 판별하는(real/fake) Discriminator는 고정하지 않고 학습을 계속 이어가는 방법을 사용하였다.
기존 GAN의 문제
- 논문에 보고된 바와 달리 부자연스러운 이미지를 생성하곤 함
- interpolation과 disentangle이 어려움 (특정 attribute 조절에 한계)
- 이에 따른 Image Synthesis에 한계 존재

Progressive Growing of GANs for Improved Quality, Stability, and Variation
How StyleGAN generates an image?
StyleGAN은 style transfer의 개념에서 영감을 받아 새로운 generator 구조를 제시한 논문이다.
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature.
저자들은 기존 연구들에서 이미지 합성 과정에서 다양한 관점에 대한 이해가 결부되어있음을 지적했다. 즉, 어디서 불규칙한(stochastic) 특징들 (예를 들어, 머리의 휘날림)이 유래하는지 , 또한, 잠재 공간에 대한 이해들이 부족했다. StyleGAN은 이미지를 각 스케일에 따른 스타일의 조합으로 분할하여, 전체적인 스타일 정보(coarse feature)를 담당하는 layer부터 세부적인 스타일 정보(fine detail)를 담당하는 layer로 구조를 나누었다.
이로써, 생성된 이미지의 안정적이고 높은 퀄리티 및 interpolation과 disentanglement를 안정적으로 수행할 수 있게 되어 image synthesis에 있어 다른 GAN 구조들 보다 우월한 성능을 보인다.
[StyleGAN 장점]
- 특질 분리 (Disentanglement) : 사람 얼굴 이미지 데이터가 가지는 semantic한 특질(자세, 눈의 모양, 개개인의 특이점 등)이 style이라는 개념을 통해 자연스럽게 분리.
- 부분 변화 샘플링 (Scale-specific control of the synthesis)

StyleGAN이 이미지를 생성하는 과정은 크게 mapping network f 를 통한 intermediate latent code w의 생성과, 이를 synthesis network g 를 통한 이미지로 변환이다.
- Mapping Network f + Learned Affine Transform A
- 학습한 분포로 부터 각 스타일을 뽑는 과정
- Mapping Network f
- mapping of latent space z to an intermediate latent space w
- 1 x 512 차원 latent code z를 무작위로 생성 ( 일반적으로 multi-variate Gaussian )
- f 는 8개의 mlp 로 구성된 네트워크
- 비선형변환 f 을 거쳐 1 x 512 차원 intermediate latent code w 를 생성
- Learned Affine Transform
- intermediate latent code w 에 AdaIN을 적용하기 전에 아핀 변환을 거친다.
- intermediate latent code w 가 각 스케일마다 세부적인 스타일을 표현할 수 있도록 학습한다.
- mlp (without activation)으로 구현 가능하다
- Synthesis Network g
- AdaIN(Adaptive Instance Normalization)
- AdaIN은 intermediate latent space w가 각 conv layer에서 미치는 세기를 조절한다
- 매번 다음 스타일을 거치기 전 정규화(Normalization)가 이루어져서, 한 스타일의 영향은 하나의 컨볼루션 연산에만 (주로) 영향을 미친다
- Stochastic Variation
- 각 합성곱 연산 후 비선형 변환 전에 Gaussian noise가 추가된다.
- Applies learned per-channel scaling factors to the noise input
- 노이즈는 1채널 이미지로 이루어짐
- Progressive growing
- 잎 단계에서 뽑은 각 스타일을 scale에 따라 네트워크에 들어간다.
- 앞 단계에서 뽑은 스타일을 차곡차곡 쌓아 새로운 이미지를 생성하는 과정
- 해상도는 4x4 부터 1024x1024까지 증가
- 특정 스타일을 조정하면, 그 스타일만이 이미지에서 변화
- 마지막 층은 1x1 convolution 으로 RGB로 변환한다.
- Style-based generator의 합계 파라미터 수는 26.2M이고, 기존의 Generator의 합계 파라미터 수는 23.1M이다.
- AdaIN(Adaptive Instance Normalization)
Mapping Network f

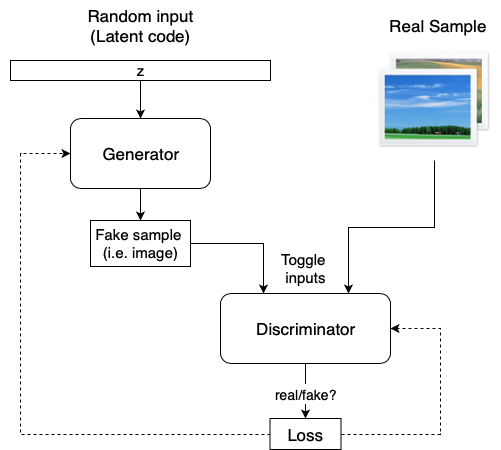
위의 이미지처럼 기존 GAN generator는 무작위로 결정된 multi-variate Gaussian이나 Unif인 latent code z가 바로 생성 네트워크에 들어가서 이미지로 변형된다
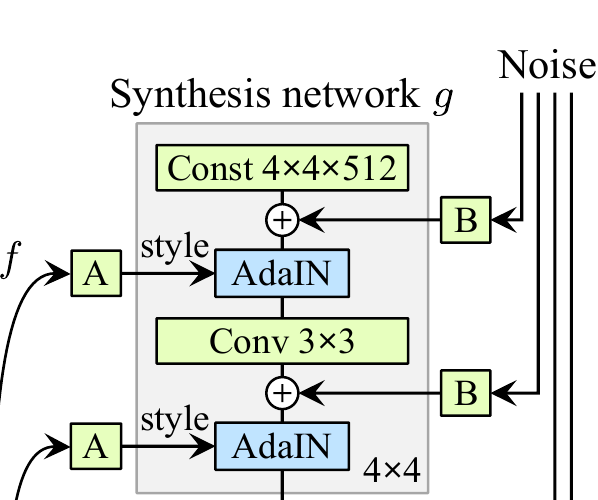
그러나 StyleGAN은a learned constant input을 사용하여, 생성자의 각 convolutional layer에서 latent code z가 mapping network를 통과하여 생성된 intermediate latent code w에 의해서 이미지의 특징을 서로 다른 scale에 따라 변형된다.

Given a latent code z in the input latent space Z, a non-linear mapping network f : Z → W first produces w ∈ W

StyleGAN은 각 이미지의 특징을 분리하여 서로 다른 scale을 따라 변형할 수 있기에, image synthesis에 매우 적합하다.
- Intuitive scale-specific mixing
- Interpolation operations
- Stochastic variation (e.g., freckles, hair)
The intuition of intermediate latent w

The input latent space must follow the probability density of the training data, and we argue that this leads to some degree of unavoidable entanglement. Our intermediate latent space is free from that restriction and is therefore allowed to be disentangled.
1. Traditional GAN's latent vector
- 일반적으로 Multi-variate gaussian에서 latent vector를 생성
- Feature Entanglement: latent vector에 대한 Prior(ex.Multi-variate Gaussian , Unif)를 미리 결정하고, 그에 대하여 데이터의 분포를 바로 맞추어야하기 하기 때문에 interpolation 또는 disentangle이 잘 되지 않았다.
- 기존 GAN의 방식대로라면 latent space가 학습 데이터의 분포를 직접적으로 따라가게 된다.
The input latent space must follow the probability density of the training data, and we argue that this leads to some degree of unavoidable entanglement
예를들어 서양인 80%, 동양인 20%로 이루어진 이미지 데이터를 가지고 generator를 학습한다면 latent space 또한 편중되어 있는 데이터의 분포를 따라갈 수 밖에 없습니다. 하지만 또다른 비선형 mapping network f를 통과시킨다면, 학습 데이터의 분포를 따라갈 필요가 없으면서도 feature들 사이의 편중된 상관관계를 줄여줄 수 있어 특질이 잘 분리된 disentangled representation을 갖는다고 주장합니다.
2. Style based generator
- StyleGAN은 latent vector Z가 비선형 변환(Fully Connected layers)을 거친 후, style W가 학습 데이터의 특질 분포를 각 scale마다 coarse/fine style을 반영.
- Affine transform A는 각 스케일마다 세부적인 스타일을 표현하도록 학습된다.
Synthesis Network g
the synthesis network g consists of 18 layers— two for each resolution (4x4 − 1024x1024 ).
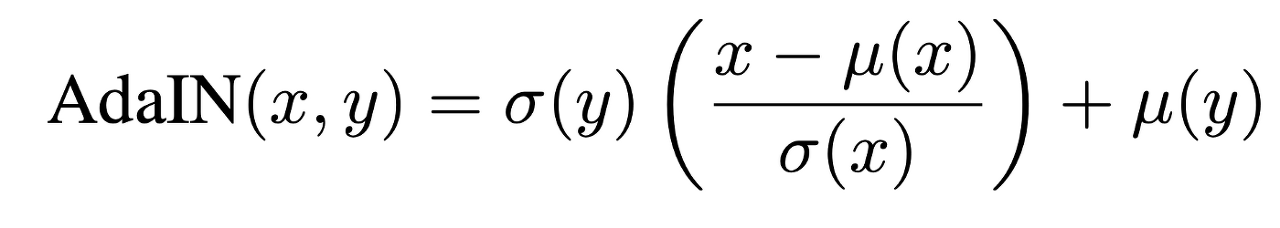
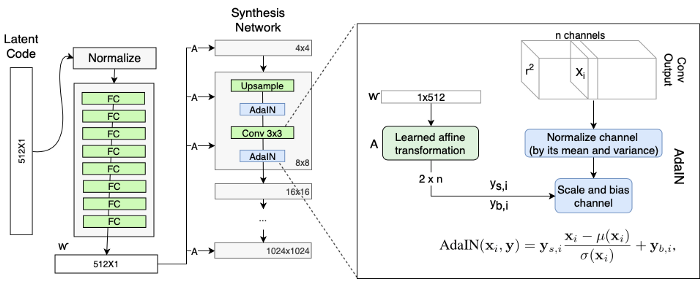
where each feature map x_i is normalized separately, and then scaled and biased using the corresponding scalar components from style y. Thus the dimensionality of y is twice the number of feature maps on that layer
서로 다른 이미지를 만들어내는 스타일들을 섞어서 이미지를 만들어내면, 스케일마다 다른 특성을 갖는 새로운 이미지를 얻을 수 있다.
AdaIn의 특징은 Instance Normalization등의 정규화 방법과 달리, 스타일과 콘텐츠 이미지의 총 합량만 정규화하고, 학습 파라미터를 사용하지 않는다는 점이다. 이에 따라 훈련 데이터에서 본 적 없는 스타일이라도 스타일 변환이 가능해졌다.
StyleGAN중에서 AdaIn은 아래의 수식을 사용한다. 정규화된 콘텐츠 정보에 스타일을 사용한 선형변환을 적용한다는 개념은 변화하지 않고 있지만, 스타일의 표준편차와 평균치 대신 뒤에서 설명하는 스타일 벡터 W에 선형 변환을 더한 y_s, y_b라는 2개의 값을 사용한다.

Mixing Regularization
- 서로 다른 두 latent vector z_1, z_2가 mapping network 를 거쳐 생성된 w_1, w_2 를 synthesis network의 여러 scale에 섞는다.
- 두 style을 섞는 방법은 여러가지가 존재하지만, 저자들은 특정 지점을 기준으로 이전 convolutional layer에는 w_1 그리고 그 후에는 w_2를 넣어준다.
- 인접한 특질 사이의 correlation을 없애기 위함.
- "This regularization technique prevents the network from assuming that adjacent styles are correlated."
- Z의 각 차원의 값들은 독립적이지만, W는 독립적이지 않을 수 있다.
- 저해상도(4x4 ~ 8x8, Coarse Styles)
- 얼굴의 방향, 머리 모양, 안경과 같은 대략적인 source의 요소가 이미지로 표현되는 한편, 눈, 머리, 명암과 같은 색이나 얼굴의 특징은 destination의 요소가 표현되어 있다.
- pose, general hair style, eye glasses
- 중간 해상도(16x16~32x32, Middle styles)
- 얼굴의 특징, 머리 모양, 눈의 특징이 source요소로, 머리의 방향이나 얼굴형이나 안경은destination의 요소로 구성되어 있다.
- smaller scale facial features, hair style, eyes open/closed
- 고해상도(64x64~1024x1024, Fine Styles)
- 기본적으로 저해상도로 입력된 Style의 영향이 커지는 경향이 있고, 저해상도부터 B의 잠재변수를 사용한 얼굴의 형상이나 피부의 색, 성별, 연령 등이 B에 가까워진다. 그러나 고해상도로 입력되면 배경이나 머리카락의 색 정도밖에 영향을 주지 못한다.
- color scheme and microstructure

"Our generator automatically separates inconsequential variation from high-level attributes."
즉, latent w / style에서 끝이 아니라, noise에 따라서도 달라진다. 또한, 앞서 style과 같이 각 생성자의 layer에서 다양한 scale에 따라 "inconsequential variation" 에 관여한다.
- high-level attributes: latent code w
- inconsequential variation: noise maps
Stochastic Variation
동일한 인물이더라도 머리카락의 위치, 피부, 주근깨, 모공과 같이 불규칙하게 나타나는 특징들이 존재한다.
고전적인 생성자(generator)가 stochastic variation을 생성하는 방법은 초기 layer에서부터 불규칙한 값을 주입함으로써 만들었었다.
- Consumes network capacity
- Hiding the periodicity of generated signal
- Not always successful


각 convolution을 거친 결과값에 per-pixel noise를 추가하여 준다. 또한, noise를 추가할 때 학습된 scale에 따라 broadcast하여 더해준다. 이에 따라, stochastic variation도 scale-specific하게 변형된다. 따라서, 기존 generator 구조처럼 초기에만 noise를 추가하는 것이 아닌, 각 layer마다 새로운 noise를 추가할 수 있고 이는 국소화된 효과를 줄 수 있다.
Truncation Trick
We can choose strength at which style is applied, with respect to an "average face"

- Low truncation: high quality , no broken images , limited variation
- High truncation: high variation, frequent artifacts , some broken images
- Negative truncation: "anti-face", 일종의 반대 되는 데이터를 보여준다.
By selecting the strength appropriately, we can get good images out every time (with slightly reduced variation)

학습이 마무리 된 후에 truncation trick을 적용하여 생성 이미지 사이의 variance/quality 보상 관계를 통해 생성할 수 있다.
Disentanglement Study
특질 분리가 잘 되었는 지에 대해 측정할 수 있는 metric을 제시한다.
Goal is a latent space that consists of linear subspaces, each of which controls one factor of variation.
- Perceptual Path Length:
- Measure how drastic changes the image undergoes as we perform interpolation in the latent space.
- 특질 분리된 정도를 측정
- Interpolation을 할 때 이미지의 특징의 변화를 측정하는 metric
- 특질 분리가 잘 될수록 interpolation을 통한 결과의 특징값이 부드럽게(smooth) 변해야한다.
- perceptually-based pairwise image distance: a weighted difference between two VGG16 embeddings
- slerp, lerp
- Linear Separability
- 특질 분리가 잘 되어 있다면, 하나의 factor에 대해서 consistent하게 변하는 direction vector를 찾을 수 있어야 한다.
- linear hyperplane (linear SVM)으로 각 factor에 대하여 서로 다른 집합들로 분리가 잘 되어야 한다.
Limitations
water droplet artifacts
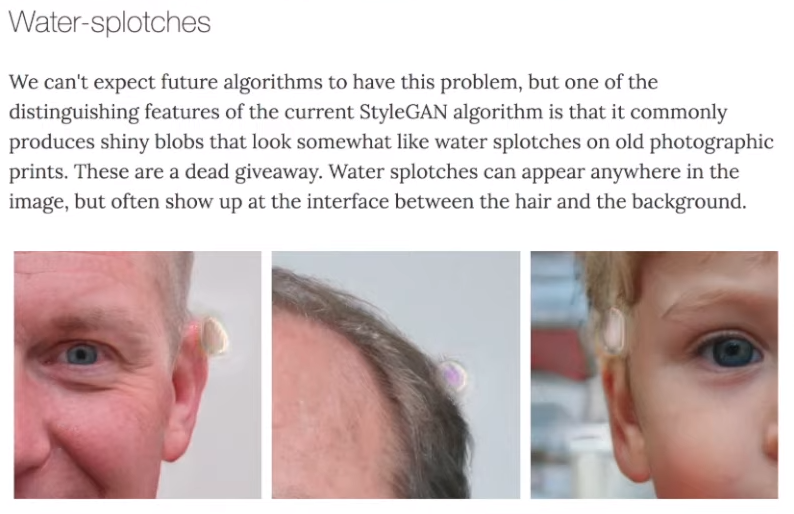

phase artifacts

- Progressive Growing appears to have strong location preference for details like teeth and eyes
- Features stay in one place before quickly moving to the next preferred location
- Authors propose an alternative design that retains the benefits of progressive growing without the drawbacks
reference
'DeepLearning > GAN' 카테고리의 다른 글
| [Paper Review] GANSpace: Discovering Interpretable GAN Controls (0) | 2020.08.27 |
|---|---|
| [Paper Review]Skip-GANomaly (0) | 2020.08.12 |
| [Paper Review] GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training (0) | 2020.08.10 |
| [Paper Review] f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks (0) | 2020.08.09 |
| [Paper review] StyleGAN2 (0) | 2020.07.28 |