2021. 4. 8. 11:50ㆍ카테고리 없음
GAN의 학습을 (1) 안정적이고, (2) 빠르며, (3) 단순하고 직관적인 방법으로 해볼 수 없을까?
Wassertein GAN은 기존 GAN의 학습 불안정성과 Mode collapse 문제를 해결하기 위해 제안 되었지만, weight clipping 혹은 gradienty penalty 와 같은 조작이 필요했으며 이는 학습 상에서 더 많은 computation을 요구했기 때문에 학습이 느려진다는 단점이 있었다.
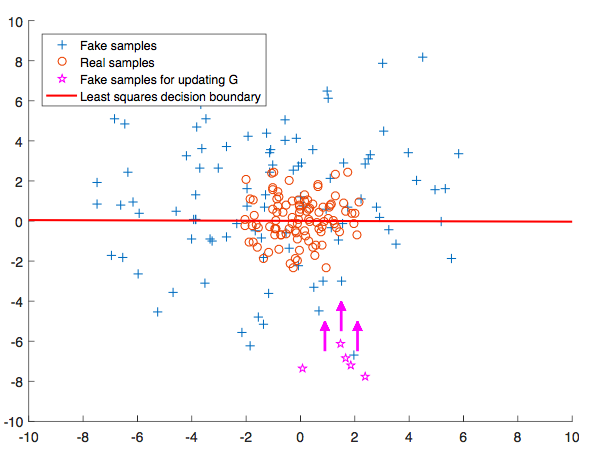
기존 GAN 목적 함수의 문제는 아래 도식에서 나타나듯이, 판별자의 decision boundary에서 먼 곳에 위치한 sample에 대해 생성자가 충분히 학습할 수 없다는 점이다. 이미 충분히 잘 속이고 있는 ☆ 샘플들은 real sample들이 몰려있는 decision boundary로 부터 먼 곳에 위치하고 있기 때문에, decision boundary로 끌고 올 수 있는 방법이 필요하다.

이는 LSGAN에서 decision boundary로 부터 거리가 먼 sample에게 거리에 따른 적절한 loss를 제공하여 생성자가 올바르게 학습하도록 유도할 수 있다. 이로써, real과 fake의 분포가 동일하도록 만들고 싶은 GAN의 목표를 더욱 잘 달성 할 수 있다.
LSGAN은 (1) smooth 하며, (2) non-saturating gradient의 성질을 갖는 목적 함수를 통해 구현된다.
논문에 따르면 LSGAN의 목적함수는 Pearson Chi square divergence를 최소화하도록 모델을 최적화한다고 설명한다.
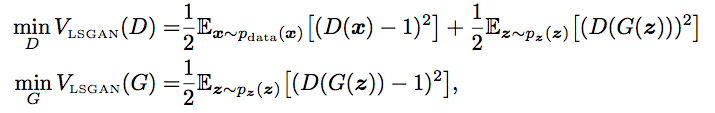
Implementation
아래와 같이 간단히 loss를 바꾸는 것이기 때문에, 기존 GAN의 목적 함수만 아래 두 줄로 변경하면 된다.
D_loss = 0.5 * (torch.mean((D_real - 1)**2) + torch.mean((D_fake - 0)**2))
G_loss = 0.5 * torch.mean((D_fake - 1)**2)