WGAN
2021. 4. 7. 09:54ㆍ카테고리 없음

Wasserstein GAN with Gradient Penalty (WGAN-GP)
Goals
Wasserstein GAN은 GAN의 대표적인 문제인 학습 불안정성과 mode collapse를 해결하고자 새로운 목적함수, W-Loss를 제안 한다. 또한, WGAN의 Lipschitz continuity 조건을 만족시키기 위해서 초기 형태인 WGAN-CP 그리고 더 발전된 형태인 WGAN-GP가 제안되었다.

- WGAN-CP: Wasserstein GAN using Weight Clipping
- WGAN-GP: Wasserstein GAN using Gradient Penalty
Fun Fact: Wasserstein is named after a mathematician at Penn State, Leonid Vaseršteĭn. You'll see it abbreviated to W (e.g. WGAN, W-loss, W-distance).
- Generator loss: critic의 생성 이미지 판별값에 음수(-)를 취함.
- Critic loss: critic의 실제 이미지와 생성 이미지 판별값 그리고 Gradient penalty.

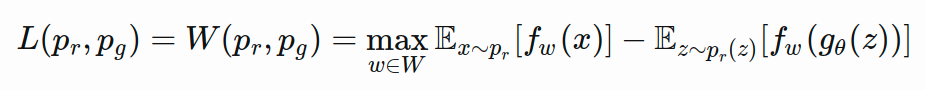
Implementation
def get_gen_loss(crit_fake_pred):
'''
Return the loss of a generator given the critic's scores of the generator's fake images.
Parameters:
crit_fake_pred: the critic's scores of the fake images
Returns:
gen_loss: a scalar loss value for the current batch of the generator
'''
gen_loss = -crit_fake_pred.mean()
return gen_loss
def get_gradient(crit, real, fake, epsilon):
'''
Return the gradient of the critic's scores with respect to mixes of real and fake images.
Parameters:
crit: the critic model
real: a batch of real images
fake: a batch of fake images
epsilon: a vector of the uniformly random proportions of real/fake per mixed image
Returns:
gradient: the gradient of the critic's scores, with respect to the mixed image
'''
mixed_images = real * epsilon + fake * (1 - epsilon) # Mix the images together
mixed_scores = crit(mixed_images) # Calculate the critic's scores on the mixed images
# Take the gradient of the scores with respect to the images
gradient = torch.autograd.grad(
inputs=mixed_images, # take the gradient of outputs with respect to inputs.
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
return gradient
def get_crit_loss(crit_fake_pred, crit_real_pred, gp, c_lambda):
'''
Return the loss of a critic given the critic's scores for fake and real images,
the gradient penalty, and gradient penalty weight.
Parameters:
crit_fake_pred: the critic's scores of the fake images
crit_real_pred: the critic's scores of the real images
gp: the unweighted gradient penalty
c_lambda: the current weight of the gradient penalty
Returns:
crit_loss: a scalar for the critic's loss, accounting for the relevant factors
'''
crit_loss = -crit_real_pred + crit_fake_pred + c_lambda * gp
return crit_loss.mean()Summary
- 학습은 안정적으로 변하고 mode collapse 문제를 해결한다.
- 그렇지만, 생성된 이미지의 질이 좋아지는 것은 아니다.
- Gradient Penalty를 계산해야하기 때문에 학습이 느려진다.
- critic을 generator보다 많이 update 한다.
- 이는 단지 학습 구조에 따른 차이로, 일반적으로 GAN에서는 generator를 critic보다 많이 학습한다.
References