2020. 12. 14. 11:26ㆍ카테고리 없음
Super-resolution
- Satelite
- Medical
Limitations of Mean-Squared-Error
Super-resolution은 low-resolution에서 high-resolution으로 문제이기에 가능한 solution이 여러 가지가 가능하다. MSE는 가능한 여러 solution 중에 평균을 취하기 때문에 blurry한 reconstruction을 갖는다. 또한, perceptual distance를 반영하지 못하는 metric이다. SRGAN은 VGG를 이용한 feature map에서 mse 기반의 perceptual loss와 GAN loss 를 결합한 형태를 목적 함수로 제안한다.

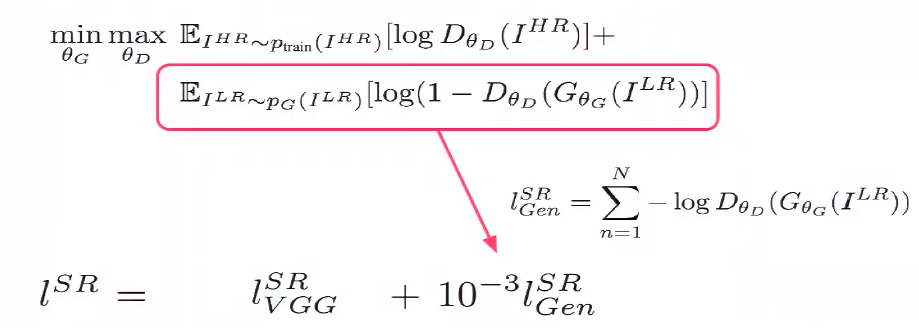
Feature distance에서의 평균값을 찾게된다면 blurry한 image reconstruction을 갖지 않게 된다. 또한, Discriminator는 실제 이미지의 분포를 이해할 수 있기 때문에 출력된 이미지를 natural image domain에 놓이도록 유도한다.
Metrics
PSNR과 SSIM과 같은 고전적인 metric은 blurry한 복원을 가져오더라도 low-frequency 를 잘 복원할 경우 좋은 결과라고 판정하게 된다. 즉, high-frequency를 측정하는 데는 취약하다. 이에 따라 논문에서는 사람이 직접 점수를 할당하는 MOS를 사용한다.
Experiments
VGG19의 깊은 feature map을 사용하는 게 더 좋은 복원 성능을 보였다.


VGG는 feature map 5,4를 사용하는게 제일 좋았는데, 이는 네트워크가 깊어질수록 주어진 데이터에 대한 content를 집중하기 좋게 되기 때문이다. 이러한 점에서 저자들은 VGG feature distance loss 를 "Content Loss"라고 부른다. GAN loss 또는 Adversarial Loss는 이미지의 texture를 판단한다고 주장한다.
- VGG loss: focus purely on the content
- Adversarial loss: focus on texture details
저자들의 실험에 따르면, text나 structured scene에 대한 reconstruction은 아직 도전적인 문제이며 현재의 모델로는 잘 복원되지 않는다고 한다. 또한, 단순 pixel difference가 아닌, 이미지의 spatial content를 담을 수 있는 content loss function (논문에서의 vgg based content loss)를 개발하는 것이 직접적인 성능 향상에 도움이 될 것이라고 한다.
super-resolution은 어느 도메인에 적용하는 지에 따라 최적의 목적 함수가 달라질 수 있다고 한다. 예를 들어, 의료 영역에서 요구하는 super-resolution은 타 영역에서 요구하는 것이 다를 것이다.
Summary
- Training data is important
- Improved techniques to train GANs are desirable
- Good objective functions are important
Thoughts
- VGG perceptual loss와 GAN loss 둘 중 어떤 것에 의해서 더 좋은 결과가 나온 것인지 불분명
- VGG만 사용한 경우에 대한 실험 결과도 궁금하다 (SRResNet + VGG54)