[논문 리뷰] One Model to Reconstruct Them All: A Novel Way to Use the Stochastic Noise in StyleGAN
2020. 12. 14. 10:45ㆍ카테고리 없음
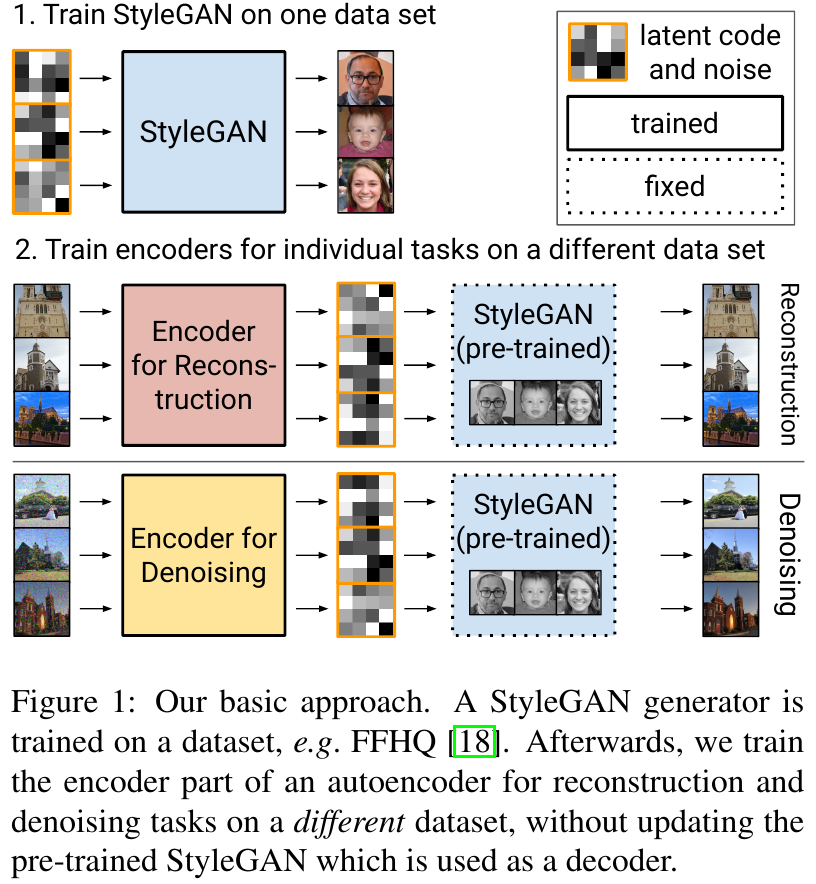
StyleGAN 기반의 오토인코더 구조를 제안하였고, 기존 Image2StyleGAN 논문에서도 밝혀졌듯이 추가적인 학습 없이도 다양한 도메인 데이터를 복원할 수 있음을 보인다. 본 논문의 contribution은 stylegan의 noise에 대해서 탐구하여 얻은 결과이다.
Research Questions
- To what degree does the latent code influence the reconstruction result?
- Can the stochastic noise provide more than stochastic variations of the generated image?
- Can a generator model (i.e. StyleGAN) trained in one domain be used to effectively reconstruct images for a different do- main?
- Can an encoder model trained in one domain be effectively used reconstruct images for a different domain?
Architecture
StyleGAN의 생성자를 기반으로 한 Decoder에 대한 구조 변경은 전혀 없다.
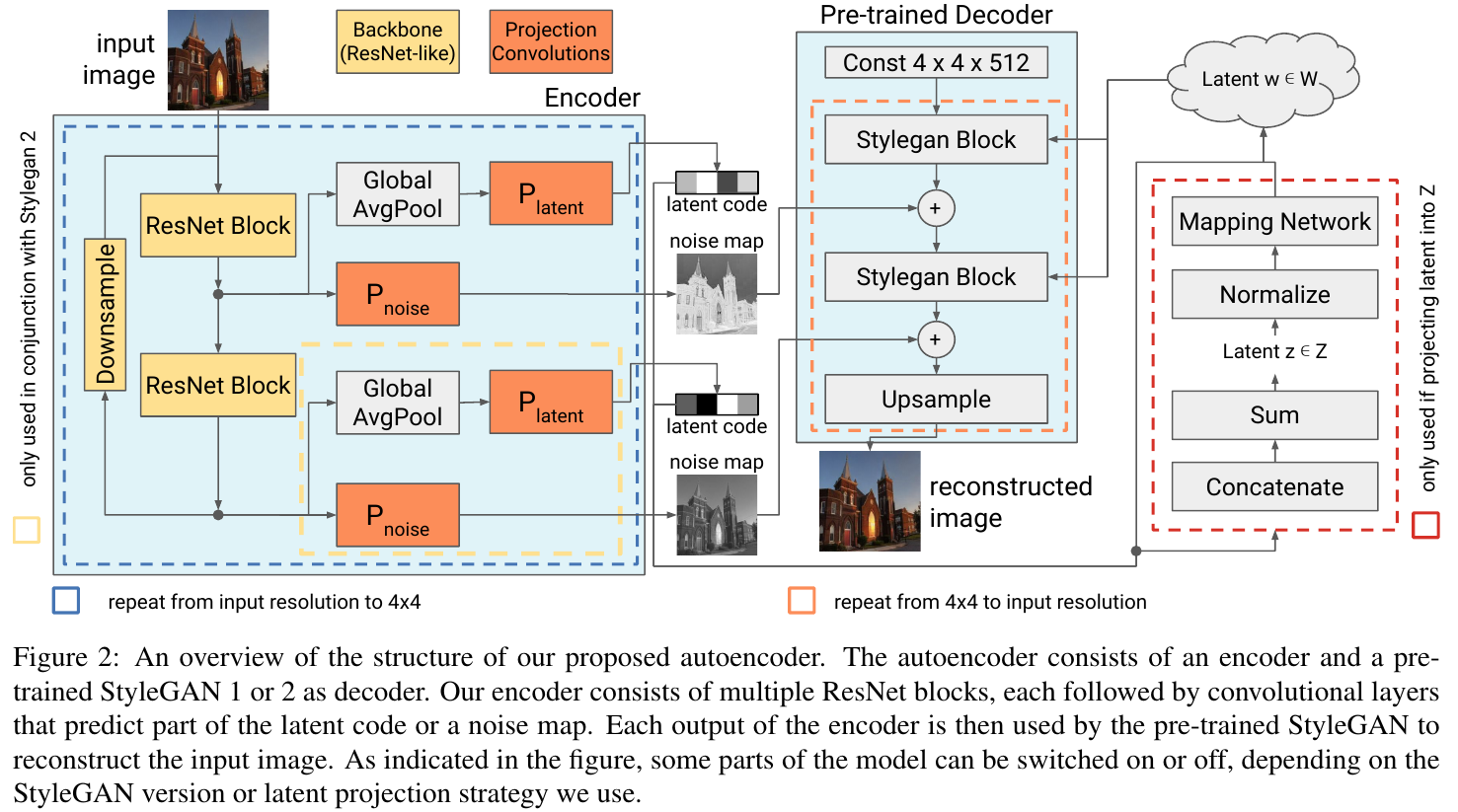
Encoder
- FCN (Fully Convolutional Network)
- latent: ResNet
- noise: U-Net
Maximizing the Semantic Meaning of the Latent Code
- Latent w를 학습하고, noise map을 학습하는 순차적 encoder 학습법.
- Latent w가 충분히 semantic 특질을 학습하도록 함.