2020. 8. 19. 20:58ㆍDeepLearning/Medical AI
- Title: Expert-level detection of acute intracranial hemorrhage on head computed tomography using deep learning
- Conference: PNAS
- Summary:
- Architecture: PatchFCN, a patch-based fully convolutional neural network.
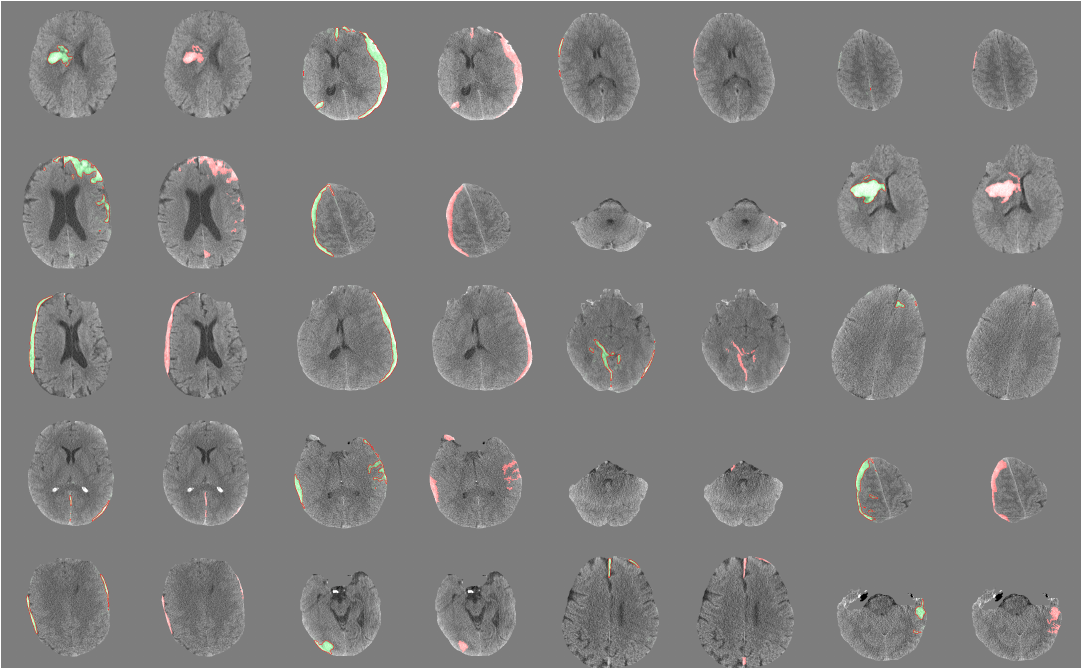
Being a workhorse in medical imaging modality, Brain Computed Tomography(CT) needs a deep learning that can accurately identify diverse and very subtle cases of a major class of pathology.
The most skilled readers demonstrated sensitivity/specificity between 0.95 and 1.00
Challenges on analyzing head CT
- need perfect or near-perfect sensitivity
- very sparse foreground, low signal-to-noise, poor contrast, and a high incidence of image artifacts
- need understanding the nature of "cross-sectional" or large 3D volume data ( > 10^6 pixels)
- Positive(disease) class pixels are extremely rare, tiny subtle abnormalities ( ~ 100 pixels )
- Domain Shift: Technical variations in the imaging process (different devices, noise, aging of the components and so on)
- Expansion of hemorrhage on any individual case is variable and unpredictable
- cannot rely solely on hyper density relative to brain in order to identify acute hemorrhage, but must also use other more subtle features
- patient-to-patient variability in pathological manifestations of disease.
- CT Artifacts
- motion artifact, "streak" artifact near the skull base or in the presence of metal
Data pre-processing
- Bone extraction: Skull and Face were removed from CT images to retain only the intracranial structures.
PatchFCN
On the previous paper, PatchFCN for Intracranial Hemorrhage Detection found patch-based FCN outperforms FCN by finding an optimal trade-off between batch diversity and the amount of context.
PatchFCN for Intracranial Hemorrhage Detection 연구에서는 FCN보다 PatchFCN 이 왜 더 좋은 지에 대하여 분석적으로 다룬 논문이 없기에 이에 대하여 다양한 요인들을 확인하였다.
Factors of the performance gains of PatchFCN:
- batch diversity
- amount of context (patch size)
- sliding window inference
patch 기반의 접근법을 사용하는 것은 실제 radiologist들이 하는 방식과 닮아 있다고 주장한다.
The morphology of contrast region is often a crucial cue for deciding whether it represents pathologies.
즉, 외부의 추가적인 context를 사용하지 않고 형태적인 대비가 일어나는 국소 영역을 관찰함을 통해 결정을 내리는 방식이다.
또한, 작은 patch 크기는 많은 batch size 를 사용하게 되어 batch-normalization과 함께 사용할 경우 안정적으로 학습할 수 있다.
sliding window 기반의 방법을 이용하여 inference 하며
3D FCN
- '3' is enough
- a network informed by 3 consecutive image was as accuracte for pixel and examination-level classification as a network that employed 5 or more consecutive images.
- 3D CNN에서 더 적은 slice만을 활용하는 것은 더 적은 parameter로 학습하는 것을 의미하기 때문에, 적은 양의 이미지를 쌓아 3D CNN을 수행하는 것은 overfitting 방지에도 도움이 된다고 주장한다.
- 그럼에도 불구하고, 다음 연구에서 3D FCN 구조를 사용하여 전체 OCT 슬라이스를 넣었을 때 전문의보다 더 좋은 결과를 내었다.
- The "right" amount of local information
- a subset or "patch" of the 2D image (not whole images)
- The context in the craniocaudal direction: 3 consecutive images (not 5 or more consecutive images)
- 인접한 3개의 이미지를 각 채널별로 쌓는다. 이는 실제 radiologist가 조그마한 병변을 검출할 때, 관심 영역을 세밀하게 보는 것을 모방한다.
- Forcing the network to consider an intermediate amount of spatial context both in-plane and in the craniocaudal direction
- larger batch diversity to stabilize training through the use of batch normalization
- 더 큰 batch size를 이용한 것이 더 좋은 성능으로 이어지는 지에 대한 부분은 분분하다.

Thoughts
- why not use U-net?
- U-net beats the prior best method, a sliding window CNN, with large margin
- 코드 공개해줬으면..